02 경영통계학 : 자료(Data)
어원에서부터 알 수 있듯 국가에서 부터 통계학이 발달되었다. 징세와 징병에서부터 행정, 근대에 들어오면서 부터 많은 분야에서 통계가 많이 사용되었다. 지금 컴퓨터가 놀라운 속도로 발전을 했고, 예전에는 논문의 데이터를 분석하려면 1주일이 넘게 걸렸는데, 지금은 더 빠른속도의 방대한 양의 계산을 할 수 있다, 점점 더 많은 양의 데이터를 분석할 수 있다.
전수조사를 하지않는 이유는?
시간과 물리적인 한계 때문이다. 전수조사가 어렵기 떄문에 샘플링 한다.
기술통계 vs 추론통계
1) 기술통계 : 자료를 적절하게 그림 도표 수치로써 설명한다. 특성을 요약하고 설명하는 통계이다.
2) 추론통계 : 추론(inference)을 하는 것, 우리가 얻게되는 정보는 모집단에서 추출하는 표본에서 얻는다. 표본에서 얻은 통계량을 가지고 모집단의 숫자인 모수를 예측한다. 이것이 해석 가능하냐 안하냐, 즉 표본에서 얻은 평균값이나 분산, 표준평가의 대표값들을 통해 실제 모집단의 값을 예측하는 것이다.
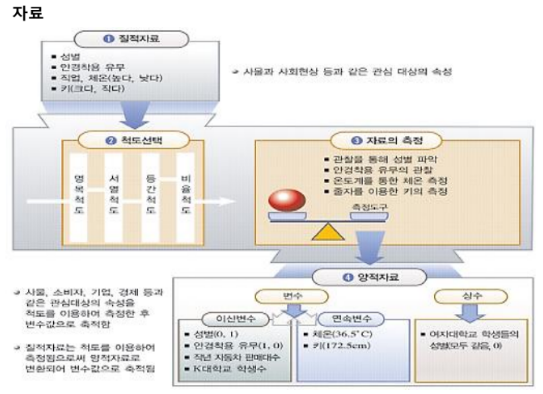
자료(data)

통계는 자료로 부터 시작된다. 어떻게 자료조사를 할 것이고, 누구에게 할 것이고, 내가 궁굼한 모집단은 누구이며 이런것들을 리서치디자인을 어디서부터 시작할 것이고 어떤 자료를 수집을 할 것이냐가 바로 첫 걸음이다. 자료는 문서나 숫자 등 다양한 형태로 존재한다. 자료가 통계의 첫걸음인데 거꾸로 이야기를 하면 정확한 자료가 구해지지 않으면 아무리 뛰어난 통계학자, 통계분석을 하더라도 그 결과는 신뢰할 수 없다. 'Garbage in Garbage out'이라고 하는데 잘못된 데이터는 그 결과를 신뢰할 수 없다. 아무리 뛰어난 요리사라고 하더라도 식재료가 좋지 않으면 요리가 맛있을 수 없는 것과 마찬가지다. 자료는 관심의 대상을 선정하고 대상의 특정한 속성을 척도를 이용해서 측정한 다음 변수 값으로 축적하여 만들어진다.

위 이미지에서 척도는 무엇인가?
1.2.3.4 문항에서 3번과 4번은 1과 2번은 반대로 물어본다. 1,2는 만족하느냐, 3, 4번 항목은 리버스 항목이다. 왜 역문항을 조사했을까? 왜 역코딩을 해서 조사를 했을까? 답변의 신뢰도를 얻기 위해서이다. 응답자의 신뢰도를 얻기 위해서이다. 이 사람이 제대로 응답을 하고 있느냐를 판단하기 위해서이다. 이런 형태의 설문지가 여러장이 오는데 3333으로 대답했으면 이사람은 신뢰도가 높을까 낮을까? 응답자는 일에 그냥 흥미가 없는 것이다. 잘 생각해보면 일이 보통이고, 열정적으로 일할 때도 있고 아닐때도 있고, 지루할때도 있고 아닐때도 있고, 만족할때도 있고 아닐때도 있다. 만약 4444의 답변이라면 이사람은 응답을 제대로 읽지 않았거나 신뢰도가 낮다. 설문지가 들어오면 이런 문항이 있는지 없는지 확인할 필요가 있다. 이런 응답지는 'Contamination(오염)이 되었다'라고 판단한다. 성의있어 보이려고 1515라고 답하는 경우, 전혀 안즐거운데 열정적으로 일하고, 지루하지 않은데 매우 만족하지 못한 사람이라는 응답도 마찬가지로 볼 수 있다. 이 내용은 차후 데이터의 분포나 퍼짐 정도, 수집된 패턴들에 대해 이야기 할 때 다시 이야기해 보겠다.
설문지를 받았으면 역문항이 있는지 없는지를 확인해보아야 한다. 제대로 응답 하려면 3333이거나 3을 기준으로 좌우가 나눠져야 한다. 이 설문지 문항은 리커트 5점 척도(likert 5 point scale)이다. 균일하게 간격이 벌어진 척도이다.

역문항은 코딩을 할 때 5점 척도면 6-1의 코딩을 하면 된다. 6-1=5, 6-2=4, … 6-5 : 1 이런식으로 코딩한다. ID는 개별항목이다. 4개의 문항이 4444이다. 1번 ID의 직무만족의 점수는 4점이 된다.

자료수집과정 : 분석문제를 결정을 하고, 대상자가 누구인지 파악한다.
관심속성 : 지지율이냐, 만족도이냐, 성과이냐
척도 : 무엇으로 측정을 할 것인가
측정 : 키를 잴때는 줄자로 재거나, 몸무게는 체중계를 통해 kg단위로 값을 수집한다
결과값을 변수에 측정 : 실제 값을 측정해서 변수값으로 축적 한다.
대부분의 통계학 교재에 성별은 남자는 1, 여자는 0으로 되어있다. 1이 더 크니까 남자는 좋은거고 0이 더 안좋은 것인가? 0과 1로 부여하는 이유는 그냥 구분자이다. 관심이 대상이 되는 것을 1로 놓고, 기준이 되는 것은 0으로 둔다. 안경쓴사람 1 안경안쓴사람 0 이렇게 된다. 성별이 어떤 의미를 두게 된다면, 기준값을 남자로 한다면 남자가 0, 여자가 1 이런식으로 된다.
자료의 구분

자료가 정보로 전환이 되는 순간은 가공이 몇번 되느냐, 자료가 가지고 있는 의미가 해석이 되느냐에 따라 달라진다.
자료의 구분 : 질적자료와 양적자료로 나뉜다. 수치로 표현이 되느냐 아니냐에 따라 구별한다. 직무만족도의 경우에는 일에 대한 만족도를 느끼느냐, 만족 자체는 질적자료이다. 양적자료가 숫자이다. 직무만족은 질이다. 이것을 점수화해 등간격으로 만들어진 5점 척도를 이용해 만족도라는 추상적인 개념을 숫자로 바꿔 준 것이다(1~5점), 질적자료는 얼마든지 양적자료로 바꿀 수 있다. 수치로 표시되는 것은 양적자료, 그렇지 않은 것은 질적자료이다.
양적자료는 변수와 상수가 있다.
변수 : 두 개 이상의 변동값이다. 둘 이상의 서로 다른 값을 갖는 양적자료이다.
상수 : 항상 똑같은 값을 갖는 한개의 수치값을 갖는 양적자료를 말한다.

자료에 특성에 따라서 어떤 분석방법이 달라진다. 쉽게 이야기 하면 공식이 달라지는 것이다. 공식이 달라지기 때문에 그에 따른 방법론들이 달리 사용이 된다. 이를 구별해야 후에 쉽게 적용할 수 있다.
모든 질적자료는 양적자료로 변환이 가능하다.

척도
▶ 관찰 대상의 속성을 측정하여 그 값을 숫자로 나타내는 일정한 규칙으로 질적 자료를 양적 자료로 변환 시키는데에 사용하는 도구이다. 5점척도, 4점 척도, 6점 척도 : 이 척도 중 뭐가 좋은가? 그때그때 다르다. 왜 상황에 따라 다를까? 5점을 하게 되면 보통이다 라고 응답하는 비율이 매우 높아진다. 응답하기 곤란할 때 보통이다라고 설문지 측정법의 맹점이다. 그럼 평균에 수렴하게 된다. 6점을 하게 되면 가운데가 없기에 내가 좋은지 싫은지 결정을 해야 한다. 7점 척도는 가운데를 기준으로 3개씩 선택지가 존재한다. 과연 5점과 6점을 정확하게 구별 가능할까? 2, 3점을 정확하게 구별할까? 응답자의 연령대가 다양하고 일반적인 사실을 물어볼 때에는 보통의 5점 척도를 활용한다. 응답자가 전문가이거나, 이 미세한 차이도 구별이 가능한 사람들이라면 7점 혹은 9점 척도로 측정도 가능하다.
척도의 종류

1) 명목척도 : 관찰대상이 되면 1이되고, 기준으로 삼으려면 0이다. 단순히 구별을 하는 것이지 크다작다의 개념이 아니다. 이를 명목척도라고 한다.
2) 서열척도 : 관심 속성을 측정해서 그 크기에 따라서 우선순위를 매기는 것이다.
3) 등간척도 : 상대적 크기이기 때문에 등간격으로 알 수 있다. 5점 척도가 바로 등간척도중 하나다. 사칙연산 중 +, - 가능하다.(+, -) 카드사용 금액을 일정단위로 나눠서 0~100만원 사이, 101~200사이 이런식으로 물어보는 것은 등간척도이다.
4) 비율척도 : 절대 0점이 존재한다. 예를들어 '한달에 프렌차이즈 레스토랑을 몇 회 이용하십니까?' 또는 그냥 괄호로 표기되어 있는 경우를 비율척도라 한다. (정보의 양이 가장 크며 모든연산이 전부 가능하다.)
카드값 사용량을 물어보는 경우 명목척도는 카드를 쓰냐 안쓰냐의 차이기 때문에 정보의 양이 적다. 응답자 기준에서 카드사용량을 물어보았을 때 가장 정보의 양이 많은 것은 비율척도이다. 괄호를 두고 몇만원 쓴다 라고 물어볼 수 있어 0만원 부터 1000만원 이상의 다양한 응답이 나올 수 있기 때문이다. 명목, 서열, 등간, 비율 순으로 정보의 양이 점점 커진다고 보면 된다. 서베이를 맡기게 되면 비율척도의 비용이 가장 비싸다. 따라서 많은 분석을 할 수 있다. 만약, 서열척도로 조사를 했으나 나름의 가중치를 부여해 등간척도로 바꾸면 그 데이터는 신뢰할 수 없다.

변수


원인이 되면 독립변수, 결과로 사용되면 종속변수이다. X가 Y에 영향을 미친다. X에 따라서 Y가 바뀔 수 있다라는 것이다. '직무의 만족도에 따라서 개인의 성과가 달라진다' 라고 한다면 만족이 높아지면 성과가 높게 나타날 것이다. 만족이 낮으면 성과가 낮게 나타날 것이다. X의 움직임에 따라서 Y가 달라지기에 원인변수인지 결과변수인지를 구별한다.
★아래 이미지를 이해하면 됨!

위의 표에서 계량화되어있는가는 숫자로 표현된 것인지 아니면 문자인지에 따라 질적자료와 양적자료로 나뉜다는 것을 나타낸다.